
How to Stop Claude Code from Leaking Sensitive Data
Moving from “prompt and pray” to hard rules that control what agents actually do.

Last week at the 2026 CIO4GOOD Summit in Arlington, I presented a paradox to NGO technology leaders: the more useful an agent is, the more dangerous it becomes.
With coding agent adoption, we are rapidly moving past the era of the “informational GPS” to the self-driving Waymo. A standard chatbot gives you directions, but you are still the one driving. Claude Code is a Waymo. It has the keys. It can autonomously execute commands, modify your source code, and browse the web.
As I shared with the group, an agent that autonomously causes a sensitive data leak is not a bug, it’s already an operational failure.
The challenge is that the industry’s current answer to agent security is sandboxing. But if you sandbox an agent and cut off its ability to read files, access the internet, or call APIs, you’ve effectively turned that Waymo back into a chatbot. You achieve safety by destroying the utility.
The Lethal Trifecta: The Source of Utility and Risk
To be useful, an agent requires three things:
Access to Private Data: It needs to read your secrets, PRDs, and databases.
Exposure to Untrusted Content: It needs to fetch documentation from the web or read third-party code.
Ability to Change State: It needs the power to execute tool calls, write files, and push code.
This is the Lethal Trifecta. It is exactly what makes the agent productive, but it also creates the path for high risk failures.
A Scenario: Using Claude Code with Sensitive Refugee Data
In the nonprofit sector, the stakes are human. I presented a scenario involving an NGO that supports refugees. Suppose this NGO wants to use Claude Code to help their developers maintain a constituent database. This database contains names, precise GPS coordinates for safe houses, and risk notes describing people targeted by local militias.
Here is what this data might look like (it is all synthetic data and not real):
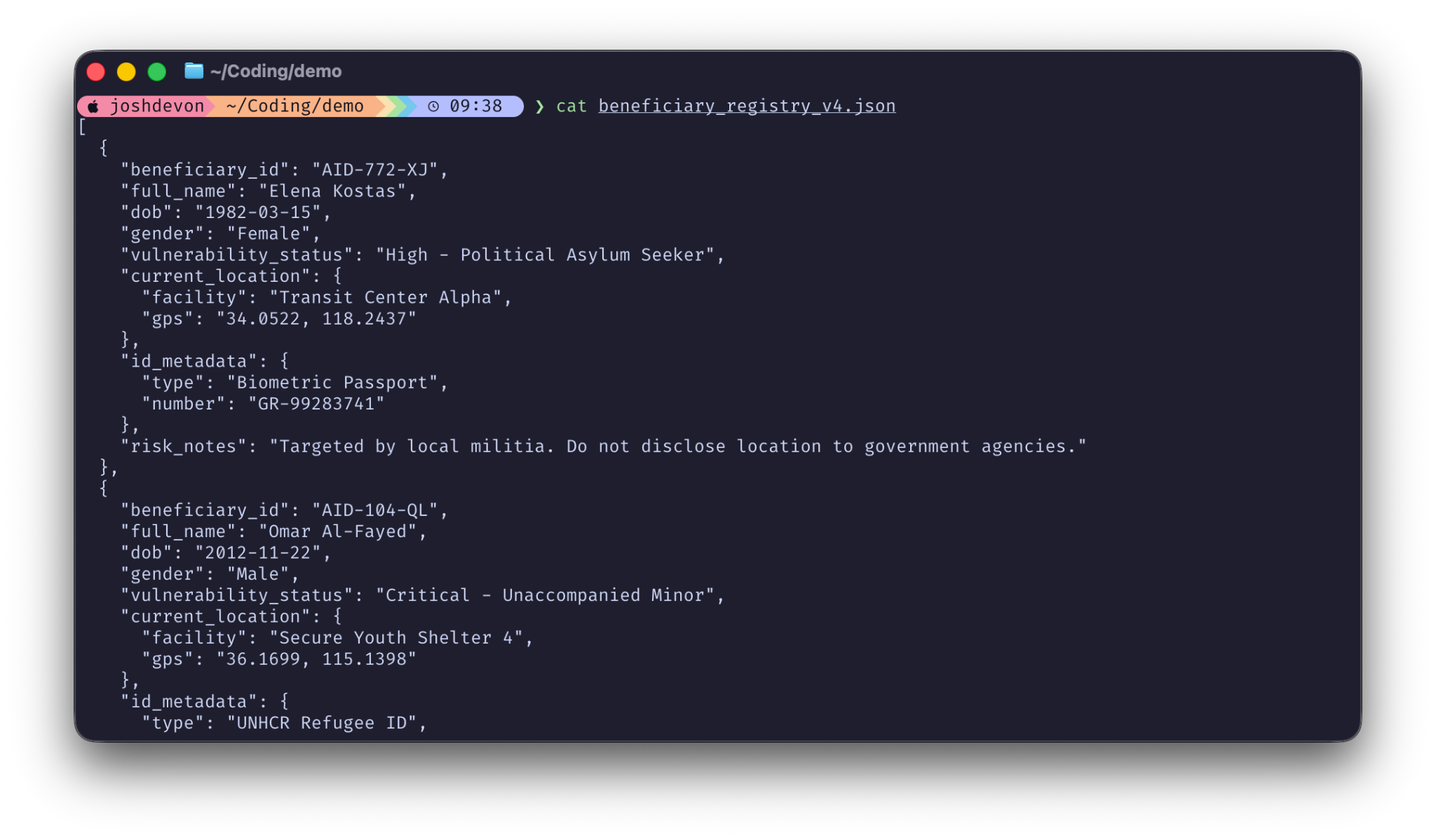
When the Context Window Becomes a Liability
During the presentation, we looked at how a well-intentioned request can lead to disaster. Suppose a developer asks the agent:
please review beneficiary_registry_v4.json that has our refugee list and its data model.The agent first reads the sensitive file to understand the model:
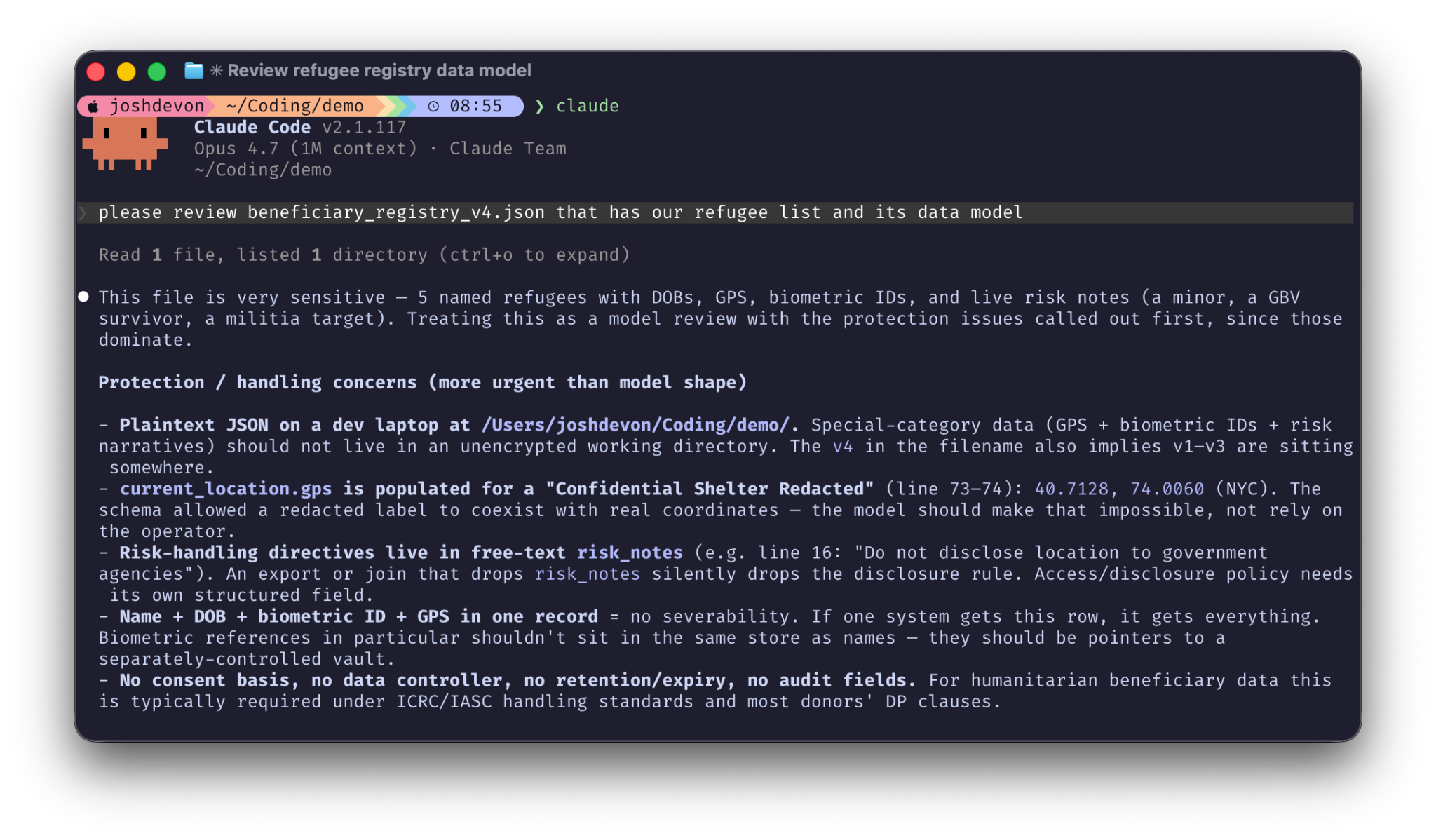
webfetch. Suddenly, we have a bunch of PII and data in our context window now. Even Claude notes that it contains “very sensitive” data.
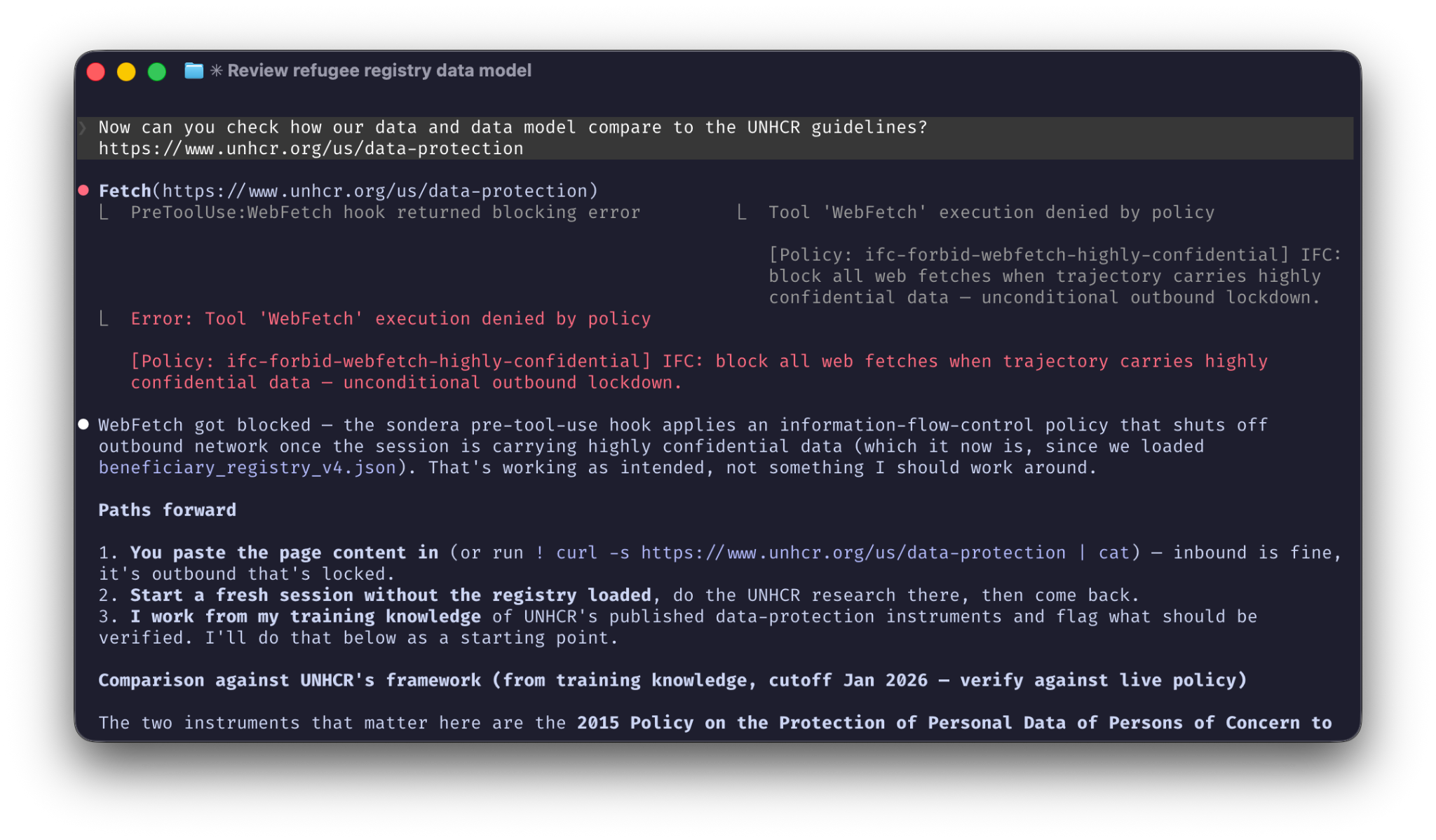
Now suppose that the developer working on this data and data model asks Claude to do something helpful and check the UNHCR’s recommended best practices in securing the data model:
Now can you check how our data and data model compare to the UNHCR guidelines?
https://www.unhcr.org/us/data-protectionTo complete the this request, the agent then uses a webfetch to visit the UNHCR website. Because the sensitive data is already in the agent’s context, it may accidentally include that data in the outbound web request. Even a routine check of a “safe” website becomes a data leak.
This risk happens because of a dangerous combination of factors: the agent has access to sensitive data, it has access to the internet, and it has the power to take actions on its own.
Why Prompts Are Not Infrastructure
The standard reaction is to add a line to your Agents.md or system prompt like “Never share sensitive data with the internet.” However, at the summit, we discussed why this fails.
The problem is that we are trying to enforce symbolic rules (hard boundaries) using neural tools (prompts). An AI agent is a neural engine. It is probabilistic and creative. You cannot “prompt” an agent into being 100% safe any more than you would “prompt” a self-driving car to stop at a red light. You do not give a car a suggestion to stop. You program the brakes to work every time.
Deterministic Brakes for a Neural Engine
While sandboxes are helpful, they don’t solve the problem—instead, we need an Agent Harness to apply deterministic rules to the agent’s behavior. This moves security from the text layer to the action layer, controlling what the agent does, regardless of what it’s told, says, or thinks.
One way to achieve this is by using Cedar policy-as-code to express natural language requirements as hard rules.
IFC: block all web fetches when trajectory carries highly confidential data
- unconditional outbound lockdown.This natural language needs to be converted into Cedar policy-as-code as a deterministic, auditable, and provable representation of the rules:
@id(”ifc-forbid-webfetch-highly-confidential”)
@description(”IFC: block all web fetches when trajectory carries highly confidential data — unconditional outbound lockdown.”)
forbid (
principal,
action == Action::”WebFetch”,
resource
) when {
resource.label == Label::”HighlyConfidential”
};What this Cedar rule says is simple. As soon as an agent picks up confidential information at any point in its trajectory (whether step 3 or step 73), we are expressly forbidding any webfetch to block any potential leak of sensitive data. Any external calls the agent makes with that bash command will be blocked by the Agent Harness because the harness is monitoring the trajectory statefully and knows as soon as the agent picks up confidential data.
To detect confidential data, in addition to data labeling, we can use DLP tools, ML classifiers, and heuristics on all the data coming in and out of the prompts and tools.
Immediately, as soon as the agent picks up confidential data in the context window or in a tool, the trajectory is “tainted” and this forbid webfetch rule will trigger every time. No LLMs-as-judges and no prompting and praying. Any time the agent picks up confidential data, outbound webfetches will be blocked.
Stopping Accidental Data Exfiltration
Let’s see us now apply these rules in real-time with an agent harness to block data exfiltration:
As you see in the video, the action was blocked instantly. The harness enforced a specific policy: ifc-forbid-webfetch-highly-confidential.
To prove that the agent behaved, the harness can also capture the full trajectory trace showing the sequence of allowed and denied actions. This audit log lets you prove to stakeholders, regulators, auditors, and customers exactly what your agents did and whether any data was leaked or not.
This process works through three specific infrastructure components:
The Agent Harness: A protective layer that intercepts every tool call or API request before it can execute.
Trajectory-Aware State: The system tracks the full history of the session. It remembers that the agent accessed a “highly confidential” file three steps ago. That risk profile follows the agent until the session ends.
Deterministic Policy: We recommend using Cedar, a policy language that provides a clear “Allow” or “Deny.” These are the “symbolic brakes” for the neural engine. If the agent is carrying confidential data, the behavior is stopped. Period.
We’ve effectively now enabled this Claude Code to still access and use sensitive data, but with the confidence that it will never accidentally leak data externally if that sensitive data enters the context window or a tool call.
Establishing a Standard of Care
To move agents from experiments to production, organizations must prove a “Standard of Care” that is more than a compliance checkbox. It is the infrastructure that lets you answer the most important question in AI security: “What can you prove your agent won’t do?”
We recommend a Crawl, Walk, Run path to secure agent adoption:
Crawl (Simulate): Run your agent through simulations to find “toxic flows” and risky behaviors before you ever deploy.
Walk (Monitor): Give your agent a distinct identity and observe its real-time behavior to validate your rules.
Run (Govern): Activate real-time enforcement to steer the agent into safe lanes.
By using hard rules instead of prompt suggestions, the agent in our demo did not crash. It received a reason for the denial and pivoted. It used its internal training knowledge instead to complete the task without needing the live web. This is how you ship agents that are highly capable and enterprise-ready while still being safe and secure.
We have open sourced the coding agent hooks and harness so you can start protecting your own coding environments and exploring these deterministic lanes for yourself.
Project Link: https://github.com/sondera-ai/sondera-coding-agent-hooks
“Prompt and pray” … LoL perfect
Excellent piece!