
Know Your Golem: Characterizing AI Agents
A framework for characterizing, monitoring, and controlling AI.


Most of us have started letting agents do real work: write our code, mutate our systems, act on our behalf. And if you’re anything like me, you feel two things at once about that. Genuinely impressed, and a little uneasy.
This is the first of three posts. Characterization, this one, is the lens: how to see an AI agent across three layers (model, system, behavior) and along a spectrum of agency. Monitoring is how you watch one in flight. Control is how you stop it. You can’t do the last two well until you’ve done the first, because the controls you pick only fit once you’ve characterized the thing you’re trying to control.
I’ll borrow an old story to get us there.
The Golem of Prague
One of my favorite grad-school textbooks, Richard McElreath’s Statistical Rethinking, opens with the parable of the Golem of Prague.
A golem is a creature of clay, animated by dust, fire, and water. In the 16th-century legend, a rabbi brings one to life by inscribing a single word on its forehead: emet, Hebrew for “truth.” Animated by truth but lacking free will, the golem does exactly what it is told. It is stronger than its makers and can accomplish more than they ever could.

But obedience without wisdom is dangerous: a careless instruction, an ambiguous command, or a situation no one anticipated can turn that power against the people around it. The golem’s abundance of power is matched by an absence of common sense.

When it became too dangerous, the rabbi wiped away one letter, turning emet into met, “death,” and the golem fell back to clay.

Hold onto three things from this story: superhuman capability, perfect instruction-following, and no judgment. And hold onto that one letter: the off switch carved into the thing itself.
AIs as modern golems
We’ve been building golems for a long time, and it was never magic, just statistics, data, optimization, and enough hardware to run the math at scale.
The lineage of this analogy runs deep. Norbert Wiener saw it coming in God & Golem, Inc., written when the golems were still statistical: the regression models and Bayesian networks McElreath writes about. Then came machine-learning golems, the support vector machines, neural networks, and classifiers. Then large-language-model golems, transformers that predict the next token from the tokens before it. And taking shape now, world models like JEPA that learn not just language but the consequence of an action: rain falls, the ground gets wet.

The clay keeps changing; the bargain doesn’t. McElreath wrote that scientists make golems. Today, engineers like us also make golems. And his warning carries over intact: “the golems of science are wisely regarded with both awe and apprehension. We absolutely have to use them, but doing so always entails some risk.”
To know what risk we’re taking on, we have to look at the golem at three layers: how it’s built, how it’s wired into a system, and how it behaves.
AI at the model layer
Start with the clay itself. A model is shaped in two phases, and they answer different questions.
Training is where it gets its capabilities. Pre-training teaches general language, broad reasoning, and world knowledge. Mid-training layers in domain knowledge. Post-training is where the behavior we care about gets elicited, like following instructions, reasoning through a problem, and calling tools. (The full pipeline is its own rabbit hole.)
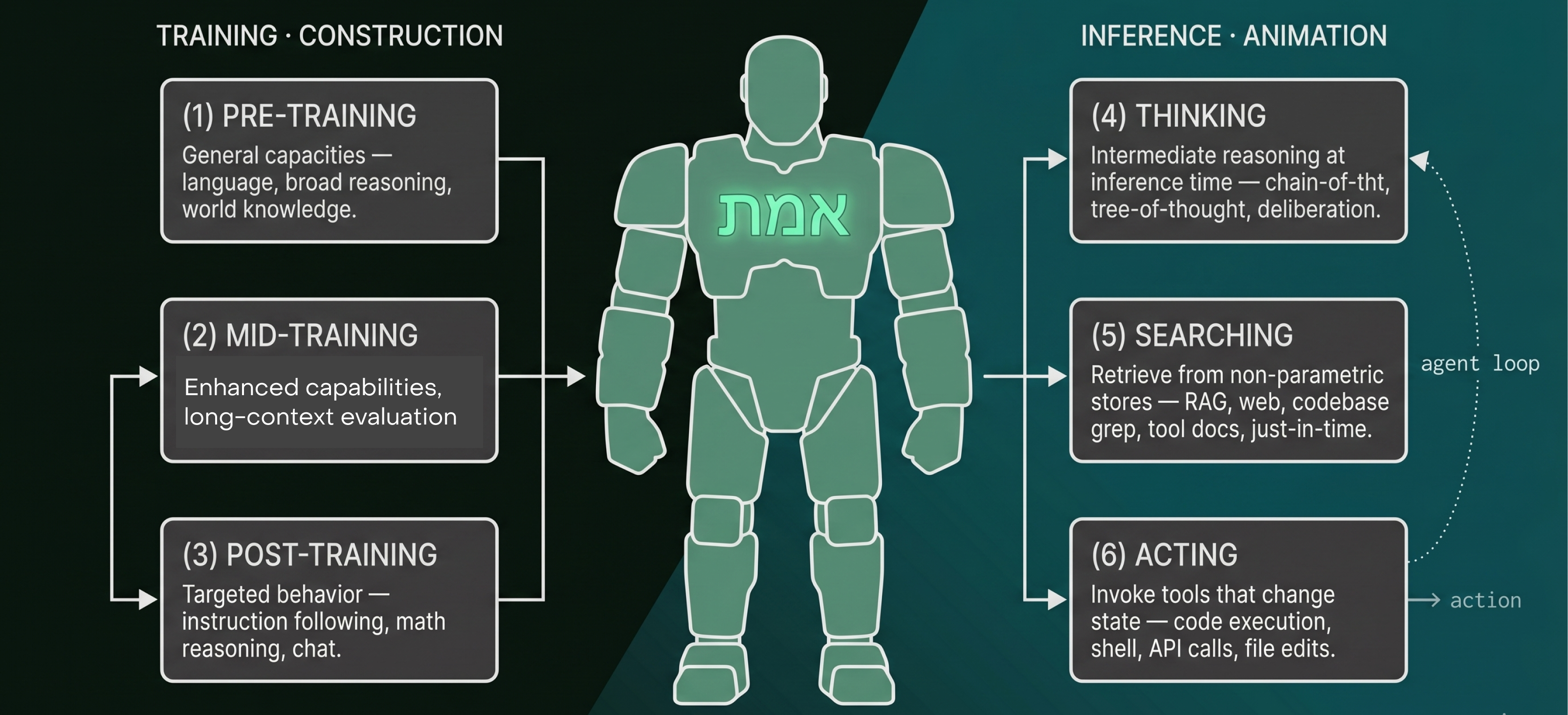
Inference is what the model does in the moment, once it’s deployed. Nathan Lambert frames a modern reasoning model around three primitives (Lambert, 2025):
Thinking: spending compute on deliberation before committing to a token (chain-of-thought, self-consistency, longer reasoning traces). Noam Brown puts the leverage starkly: one unit of test-time compute can be worth a 1,000–10,000× increase in model size (Brown).
Searching: pulling in what the model can’t carry in its weights, just-in-time. RAG indexes, web search, codebase
grep, tool docs. Anthropic frames the goal as “the smallest possible set of high-signal tokens” (Anthropic, 2025).Acting: invoking tools that change state in the world, like shell commands, API calls, and file edits. This is the one that matters most for control.
The moment a generated token becomes a real effect is where monitoring and enforcement have to live.
AI at the system layer
A model on its own doesn’t act. An agent is a model plus a harness. The model calls tools in a loop to achieve a goal; everything around it is engineering.
The scaffold and agent loop define what the agent does. The harness runs it: managing short- and long-term memory, exposing skills (procedural knowledge that bundles what’s needed to accomplish a goal), and providing tools, the affordances to take action. And agents can summon other agents. A sub-agent gets its own model, scaffold, harness, context, and reasoning. We’re increasingly building agents that spawn and orchestrate other agents.
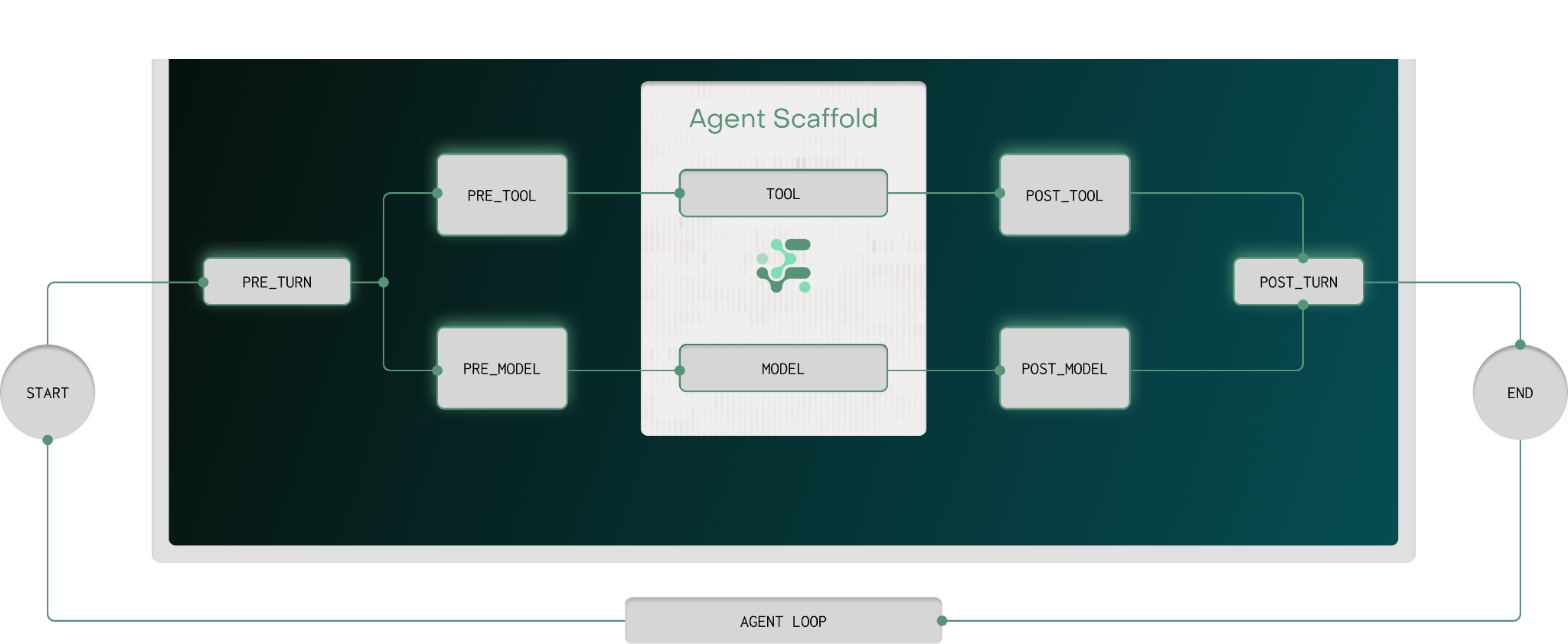
This matters for control because the harness is the part we own. We can’t open up the model’s weights, but the system layer is ours to instrument.
And the capabilities riding on top of it are climbing fast. METR’s time-horizon work shows the length of task an AI can finish on its own, measured at a 50% success rate, doubling on a steady exponential. As capability climbs, the question stops being “is it accurate on the benchmark?” and becomes “can I trust it with a real task in the real world?”
Profiling agency
Trust isn’t one knob. Agency is the capacity to act intentionally, and it spans several dimensions (Kasirzadeh & Gabriel, 2025):
Autonomy: the degree of independence. Does the agent ask permission, or ask forgiveness? As autonomy rises, the window for human intervention closes.
Efficacy: the power to change the world. It blends capability (what it can do) with permission (what it’s allowed to do). An agent that can execute code or move money has high efficacy.
Goal complexity: the planning horizon. A chatbot is one turn; an autonomous coder may run hundreds or thousands of steps, and each step adds uncertainty.
Generality: the breadth of domains and tasks the agent can operate across.

Profiling an agent on these dimensions maps where its utility comes from and where its risk comes from. That tells you how much monitoring it warrants and which controls to reach for. Classifying these profiles is how you reason about the utility–security tradeoff instead of guessing at it.
Autonomy levels with (scalable) oversight
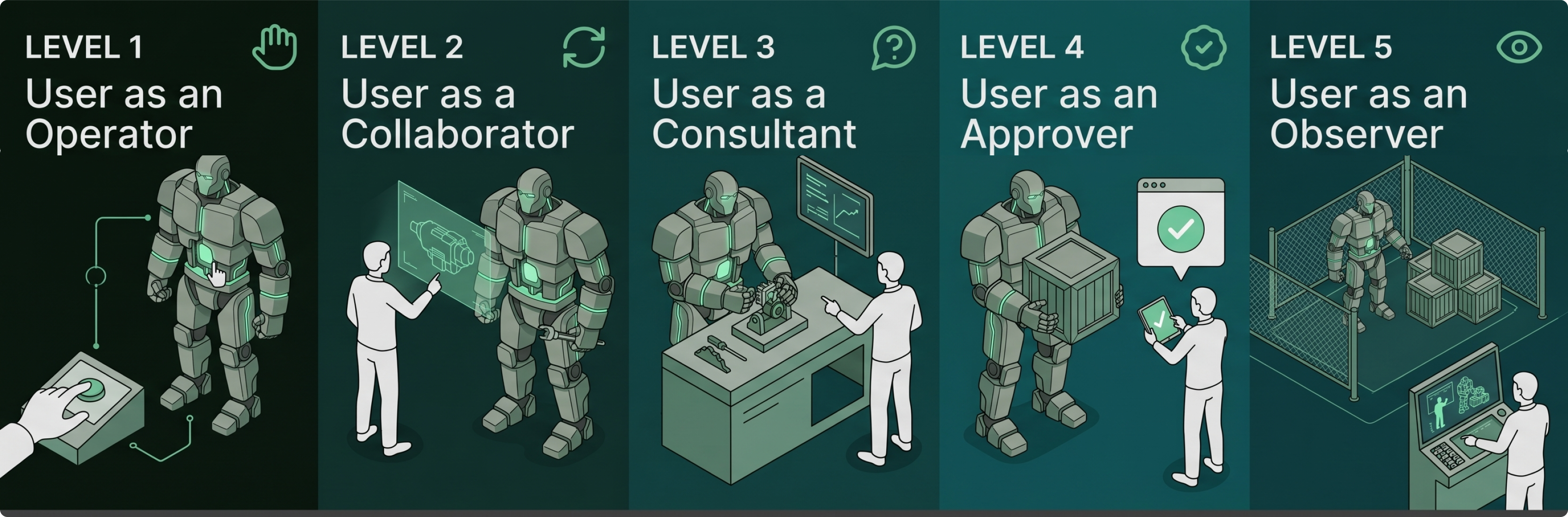
Of these dimensions, autonomy is still at the heart of agent design. Think of it as a slider. Feng, McDonald, and Zhang offer a clean five-level scale (Feng et al., 2025):
User as Operator: the chatbot. It controls nothing; you drive.
User as Collaborator: the assistant decides when to reach for a tool.
User as Consultant: the agent takes the lead and checks in for expertise or preferences.
User as Approver: the agent runs on its own and stops only on risky or pre-specified actions.
User as Observer: the agent operates with full autonomy under monitoring; you watch from the outside.
(NVIDIA offers a parallel framing tied to security controls; see Harang & Sablotny, 2025.)
As you slide from left to right, you gain utility and power, and you expand the blast radius just as fast if the agent is ever compromised or goes off the rails. Coding agents today mostly sit at Level 3 and 4, with Level 5 being “YOLO mode.”
There’s a trap right in the middle. Between Levels 3 and 4 we lean on human approval as the safeguard, but the prompts come so often that people stop reading them. Anthropic reported that users approved roughly 93% of Claude Code permission prompts, and that the more approvals a user sees, the less attention they pay to each (Anthropic, 2026). That’s consent fatigue, and it turns well-meaning controls into security theater. The goal of secure-by-design isn’t to ask permission constantly. It’s to maximize oversight while minimizing the number of times you interrupt. That’s what scalable oversight has to mean in practice.
AI at the behavior layer
So we have an agent with a profile and an autonomy level. What does it leave behind?
Behavior is a composition: what the agent is (its identity and capabilities), what it does (its effects and actions), where it runs (its scopes), and what it’s done (its trajectory, transcript, and trace).

Not every effect is equal. Some are reversible: a file written in a sandbox you can roll back. Some are compensable: a database row or a running service you can undo with effort. And some are irreversible: a payment sent, an email out the door, a model call you can never take back (Shepherd, 2026). The whole question of high stakes comes down to this: an effect stays reversible right up to the moment it materializes. After that, all you can do is audit.
This is why behavior is the hard layer. AI behavior is opaque, hard to inspect, and entangled. Models are stochastic, sampling the next token. Agentic systems are non-deterministic: the same starting point can lead to many valid paths. They’re brittle, so a tiny change in the input can swing the output wildly. Their capabilities are jagged: they’ll solve an expert problem and then trip over something a junior wouldn’t, and you can’t predict which until you test empirically (Morris et al., 2026). And they’re exposed: models still can’t reliably distinguish user instructions from data, so prompt injection (direct for jailbreaking, indirect for goal hijacking) stays live wherever untrusted content is loaded (Bagdasarian, 2025).
That opacity is why you can’t constrain the golem from the inside. Your safety rules and an attacker’s instructions live in the same context window, and the model can’t reliably tell them apart. Prompting isn’t a boundary.
Three defenses, none enough alone
If you can’t fix this from the inside, where do the mitigations go? Three nested defenses sit between an agent and the harm it can cause, and none substitutes for the others.

Alignment trains the model so what it wants matches what we want, but it lives in the weights, and you can’t verify it from outside (Amodei, 2025). Control builds system-layer protocols that hold even if the model is misaligned or deceptive, measured by the model’s capacity to subvert them, not its willingness to (Greenblatt & Shlegeris, 2025). Security engineers the system to resist a third party who tries to turn the agent against its own user.
The field is shifting from make it want good things toward this kind of defense-in-depth, because no single layer is trusted to scale to superhuman systems. Trustworthiness is broader still. NIST names seven properties at once: valid, safe, secure, accountable, explainable, privacy-preserving, and fair (NIST AI RMF). Characterization is what tells you which of those are on the line for a given agent. Monitoring and control are where you defend them.
Takeaways
Characterization comes before control. Before you decide how to monitor an agent, characterize it:
Look at three layers. The model you can’t open up. The system, the harness, is what you own and instrument. Behavior is where effects materialize and where the stakes get decided.
Profile before you protect. Autonomy, efficacy, goal complexity, and generality together tell you where utility and risk come from, and therefore what controls fit.
Mind the autonomy slider. Every notch right multiplies both utility and blast radius. Human approval doesn’t scale; consent fatigue turns it into theater. Aim to maximize oversight while minimizing interruptions.
Effects are reversible until they materialize. That single moment, when a token becomes an effect, is where a boundary has to live.
You can’t constrain it from the inside. Prompting shares a context window with the attacker. The boundary has to go outside the model, in something deterministic an attacker (or the model) can’t talk out of its rules.
When an agent has Level 4 or 5 autonomy, high efficacy, a thousand-step horizon, sitting on top of irreversible effects, the control it needs is clear. Not another approval prompt for a developer already rubber-stamping 93% of them, but a synchronous, fail-closed boundary that stops the irreversible action before it materializes. Which boundary, where it sits, and how you watch the agent walk up to it: that’s Monitoring and Control, the next two posts.
The rabbi controlled a superhuman golem with one act of writing, and then with the erasure of a single letter. But he carved that inscription inside the thing he couldn’t trust, on the forehead, where an attacker (or the model) could rewrite it. The work ahead is to take the inscription off the forehead and carve it outside, into a layer the golem reads but cannot reach. Characterizing the golem is how you decide what that inscription needs to say.